扫二维码与项目经理沟通
我们在微信上24小时期待你的声音
解答本文疑问/技术咨询/运营咨询/技术建议/互联网交流
表面上看很多步骤是为了满足团队标注这一需求(特别是外部标注团队),包括创建团队、邀请成员、创建标注作业、标注审核等等,但本质上则是安全把控和质量把控需求:
安全把控体现在管理员可以分配给团队成员不同的角色以控制成员的权限,例如标注者(Annotator)只能查看自己任务中的图片;
质量把控体现在标注完后还会有管理员审核标注情况以保证标注质量。
因此,这样复杂的链路是一个企业级标注产品应有的设计,尽管这样不可避免会造成用户认知成本的升高,以及用户体验的降低。
4.3.1 创建数据集
在Supervisely中,用户可以在一个数据集中完成4种标注(视频标注除外),即分类、检测、分割、姿态估计。
与ModelArts不同,Supervisely对数据集的定位更像是图片集。一批图片只需要导入一次,无论做哪种类型的标注都可以在同一个数据集上完成。且后续做训练时,可以直接得到一张图片上的所有标注。
综上,Supervisely统一的数据集模块,提升了图片导入,图片标注以及图片后处理的效率。但这种方式也有缺点:所有标注类型的操作模式固定,无法针对特定类型(例如Modelarts的图片分类可同时选择多张图片一起标注)做深入优化。
4.3.2 数据处理
Supervisely的数据处理模块叫做DTL, Data Transformation Language,是一种基于JSON的脚本语言,通过配置DTL脚本可以完成合并数据集、标签映射、图片增强、格式转换、图片去噪、图片翻转等46种操作,满足各类数据处理需求。

图16:Supervisely中为图片加入高斯模糊
虽然功能相比ModelArts来说更加强大,但是由于仅提供代码形式操作,仅适合工程师,然而大部分工程师已掌握通过python处理图片的方式,再额外学习一种语言无疑会增加学习成本。
另一方面这种特殊的语言对效率的提升也存在未知数,例如用户想进行某种图片操作,但调研了半天发现该语言不支持,最后还是要通过python来完成,到头来降低了效率。
4.3.3 自动标注
Supervisely目前提供了14款预训练的模型,训练用数据大部分来自COCO(微软发布的大型图像数据集),少部分来自PASCAL VOC2012, Cityscapes, ADE20K等其他公开数据集。
在自动标注部分,Supervisely的优势在于支持语义分割型的自动标注,加上产品在语义分割型的人工标注上拥有出色的体验,使这类型任务的标注效率得以大幅提升。
Supervisely的自动标注模块产品化程度较低,主要体现在以下两点:
由于本身不提供模型训练及推理服务,需要用户自行准备自动标注所需的硬件环境,且限制较多(仅支持Nvidia GPU,需要Linux和Cuda驱动)。
通过JSON格式的配置文件来配置模型推理参数(见图17)。相比华为简单的配置界面,这种形式的灵活性虽然更高,但用户真的需要那么配置还是指想系统直接给出一个自动标注的结果就好呢?

图17:Supervisely(左)与华为ModelArts(右)的全自动标注配置对比
4.3.4 人工标注
Supervisely的标注功能十分强大,主要有以下2个特点:
丰富的标注形式:为了支持各种类型的标注,Supervisely提供了多达9种的标注形式,包括:标签、点、矩形、折线、多边形、长方体、像素图、智能工具 (Smart Tool)、关键点等。
复杂的标签系统:抽象出了对象(Object),类(Class),标签(Tag)三个实体,在复杂场景中提高了实体之间的复用性。
4.3.4.1 丰富的标注形式
在所有9种标注形式中,智能工具令人印象深刻:
智能工具用于分割类型的标注,用户只需要2次点击框选一个物体,通过算法对目标进行描边即可完成一个初步的分割,再通过标注积极点和消极点完成精确标注,大大降低了分割类任务的标注成本。

图18:Supervisely中经过11次点击后完成了一个语义分割
4.3.4.2 复杂的标签系统
为了满足一个数据集涵盖多种标注类型的需求,Supervisely有一套复杂的标签系统。我们通过对3款产品的ER图来具体分析一下这套标签系统的优劣。
在图19的行人识别场景中,我们会画一个个行人包围框。那么我们就需要定义一个标签叫:行人。
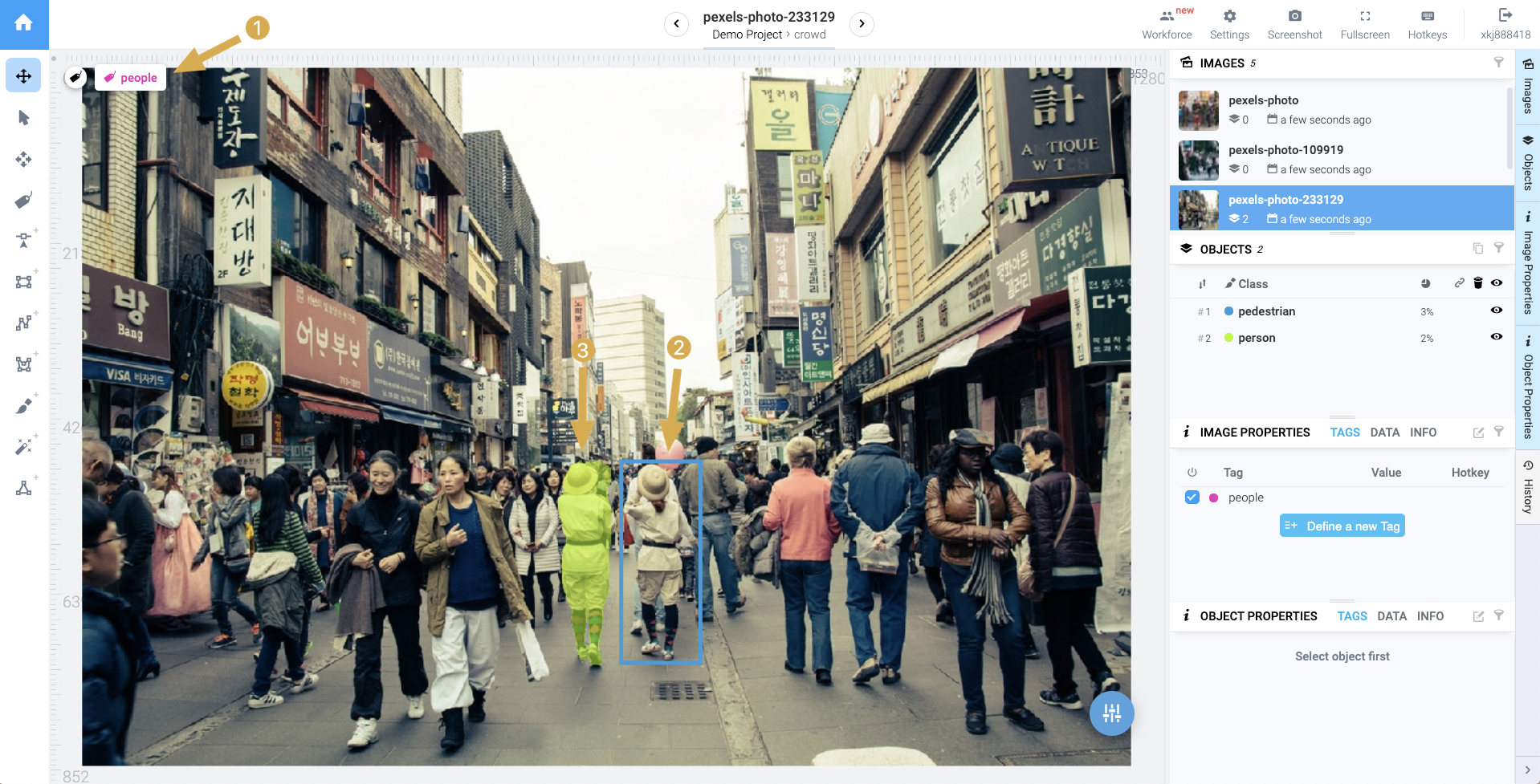
图19:Supervisely中的行人标注场景
但是每个行人的属性又有不同,例如行人A戴帽,行人B不戴帽.如果我们需要区分戴帽的行人和不戴帽的行人,一种做法是创建两个标签:戴帽的行人、不戴帽的行人。
但这样的两个标签会丧失关联性——如果模型只要检测行人,还需要对这两个标签进行转换,效率较低。
比较合理的做法是在行人标签下创建一个属性——是否戴帽;并抽象出一个概念:对象。
用户每画一个包围框,系统就会创建一个对象(例如:行人A),每个对象会对应一个标签(例如:行人),然后每个对象可以设置该标签所具有的属性值(例如:是否戴帽=是)。
CVAT和ModelArts都是这样的做法,区别是CVAT可以直接为图片加上标签,用于图片分类。而ModelArts由于划分了图片分类和目标检测数据集,因此标签仅能在图片分类型数据中被应用在图片上。
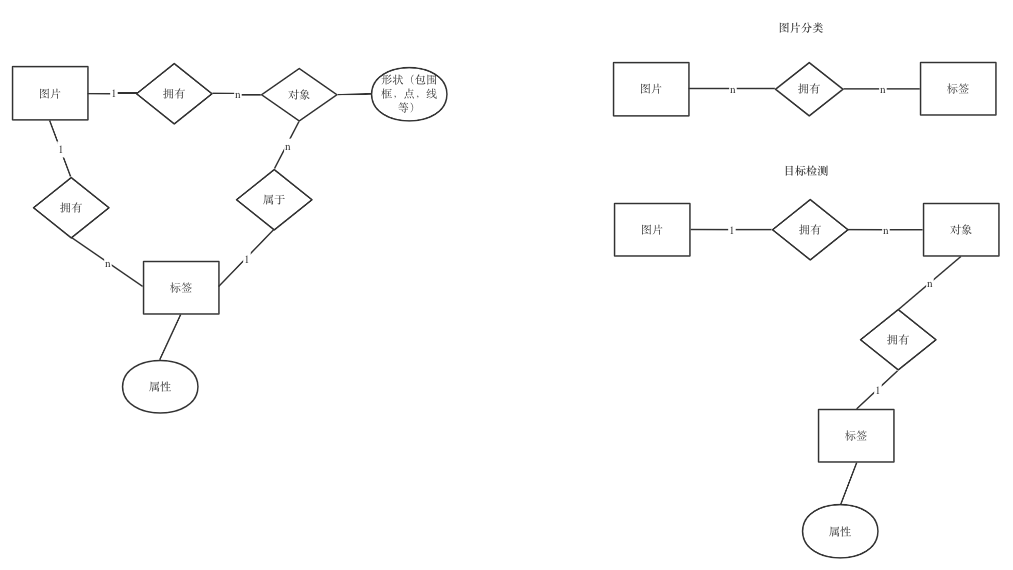
图20:CVAT(左)和ModelArts(右)的图片-对象-标签ER图对比
而Supervisely则是把标签和属性拆分成了两个实体,再通过对象实体来关联标签和属性(如下图):
这种做法可以提高属性的复用,例如在Supervisely中,用户只需要定义一遍颜色属性,之后无论是标注行人(作为一个标签)还是车辆(作为一个标签)的颜色都可以应用同一个“颜色”下面的属性,提高了复杂标注集的准备效率。
但同时这种做法对用户体验设计提出了较大挑战,从上手难度来看,Supervisely无疑是三款产品中最难上手的。
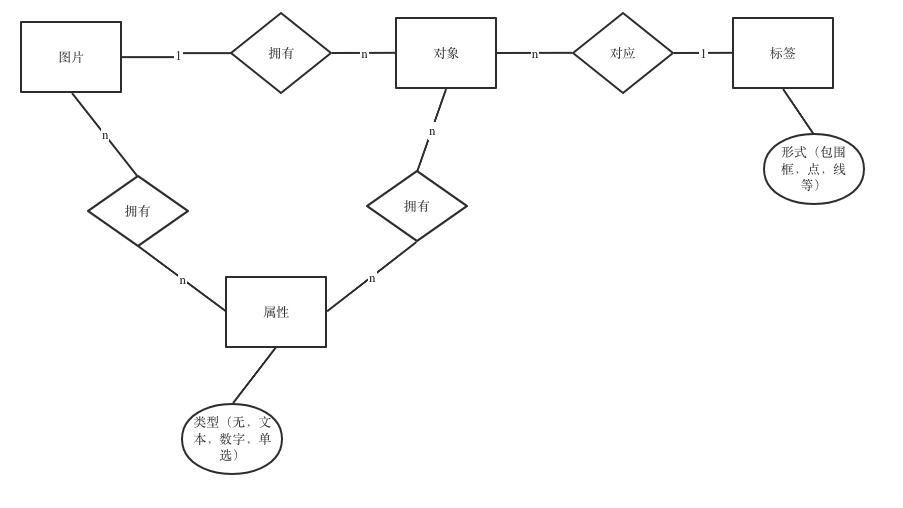
图21:Supervisely的图片-对象-标签-对象ER图
5. 总结与展望 5.1 总结对比下表为三款标注产品的功能总结:
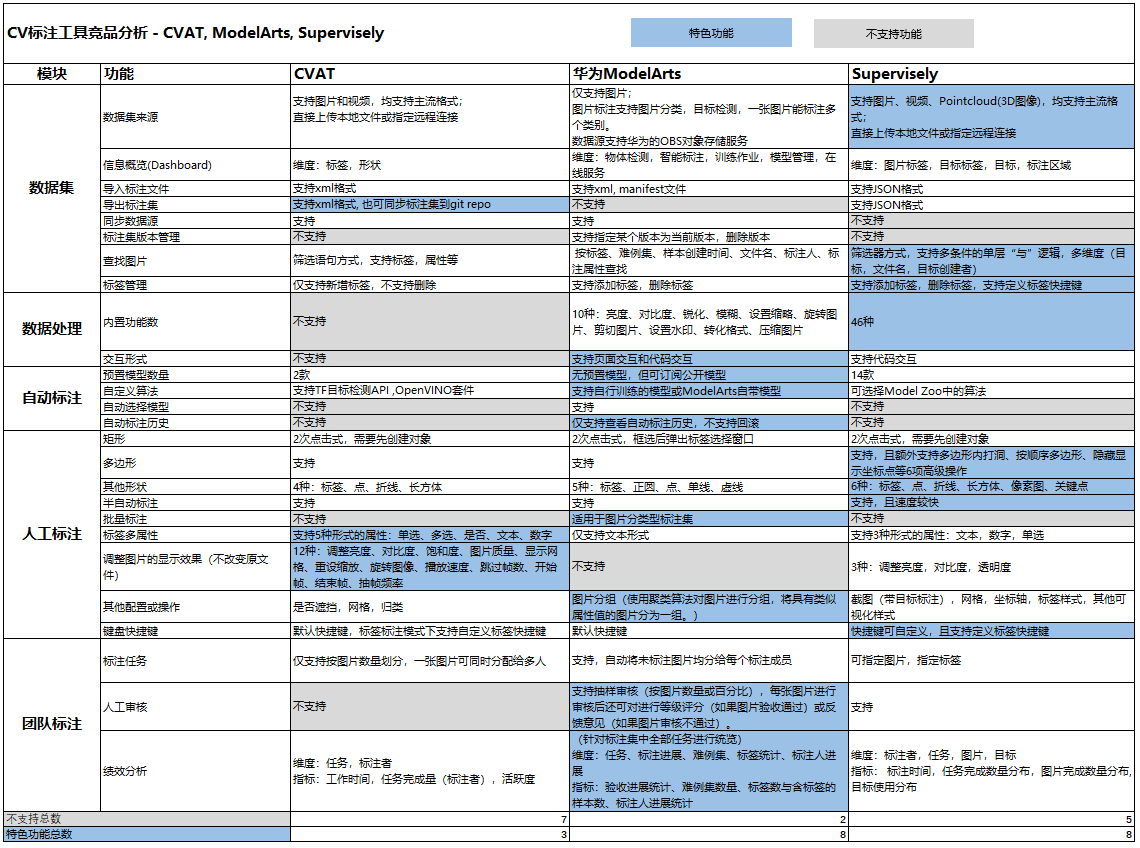
表3:三款产品的功能总结对比
CVAT: 人工标注功能最为强大,但自动标注功较为薄弱。独有的追踪模式免去了对视频的预处理,对标注效率的提升也十分巨大。CVAT的任务分析功能由于环境原因未能完全体验,从介绍来看应该会在这块发力。
ModelArts: 作为华为云的一个功能模块,ModelArts的产品战略也更加偏向通用性,平台性。通过与华为OBS系统的结合给其带来了强大的数据处理能力也强化了其平台的可拓展性和兼容性。同时自动标注和半自动标注作为ModelArts的优势是CVAT和Supervisely所不具备的,也从侧面体现了ModelArts依靠华为云所带来的强大运算力和算法优势。总体来说ModelArts是一个均衡的选手,具有优秀的业务拓展能力。
Supervisely:整体功能最为完善,适合企业级应用。对语义分割类任务支持较好,但部分功能(如数据处理,自动标注)需要通过代码方式完成,效率提升有限。
当然我们也发现有一些功能在3款产品中都没有看到,例如水印功能,会适用于保密要求的场景,如监狱,银行等。
5.2 标注工具的未来趋势5.2.1 人工标注这个环节不会消失
这其实是个悖论:假设我需要训练一个CV模型,训练模型需要准备标注好的图片,如果图片标注只需要自动标注而无需人工干预,那意味着模型已经能够准确预测出结果.
如果能做到准确预测,说明已经这个模型已经被训练完全,不再需要训练,这就和假设相悖了。
5.2.2 自动标注的价值主要体现在单个标注需要花费较长时间的标注类型中,如分割和姿态估计
既然人工标注一定会存在,那么自动标注存在意义就是提高人工标注效率,而非代替人工标注。在分类和检测任务这类单次标注耗时较短的场景中,自动标注的价值较小。
假设从0开始完成一个标注花费5秒钟,而已经进行了自动标注的情况下,修改一个标注需要花2秒,标注效率提升60%(假设跑自动标注模型是在下班之后,不影响人工标注时间)。
但我们看到可能有些图片上模型的标注结果偏差太大,这样用户还需要话1秒来删掉自动标注的结果,反而这次标注的效率降低了20%(ie., 1/5),如此高的负收益使得整体效率算下来没有提高很多。
5.2.3 人工标注的主要内容将从创建标注转变为修改标注
虽然人工标注环节不会消失,但显然自动标注将会在标注环节起到越来越重要的作用,今后常见的标注流程将会从创建一个新标注,转变为修改一个由模型创建的标注。
因此,优化修改标注时的用户体验将会是一个提高标注效率的突破点。

我们在微信上24小时期待你的声音
解答本文疑问/技术咨询/运营咨询/技术建议/互联网交流
微信二维码
移动版官网